˙Ꙫ˙
神经网络基本骨架nn.Module
1 | import torch.nn as nn |
1 | # e.g. |
卷积层 Convolution Layers
nn.Conv2d 2维卷积
1 | CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None) |
- in_channels (int) – Number of channels in the input image
- out_channels (int) – Number of channels produced by the convolution
- kernel_size (int or tuple) – Size of the convolving kernel 在训练过程中不断调整
- stride (int or tuple, optional) – Stride of the convolution. Default: 1
- padding (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0
- padding_mode (str, optional) –
'zeros','reflect','replicate'or'circular'. Default:'zeros' - dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
- groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
- bias (bool, optional) – If
True, adds a learnable bias to the output. Default:True
Shape计算

1 | import torch |
常用卷积层
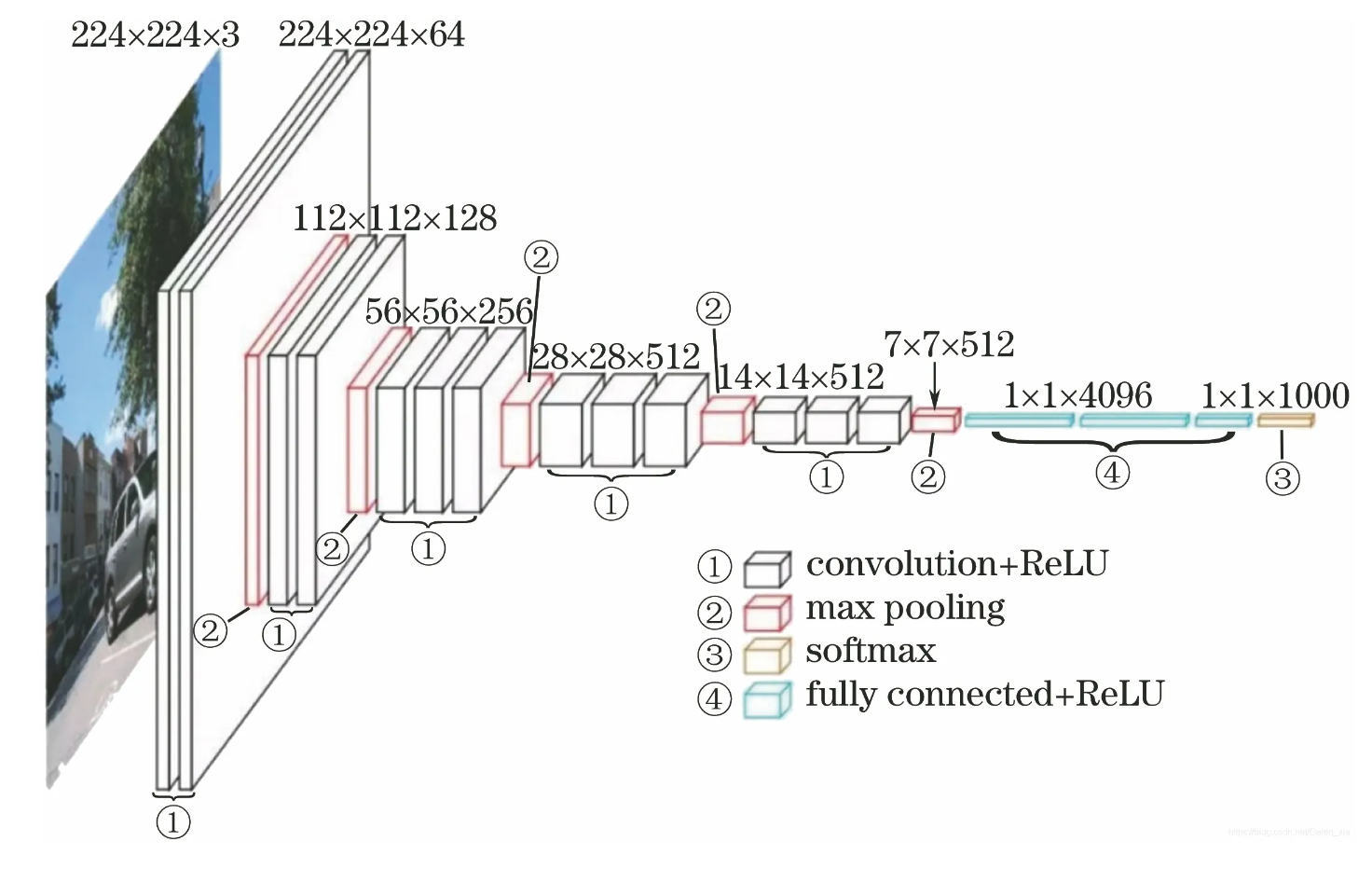
VGG16 注意设置的padding大小
池化层 Pooling layers
MaxPool2d最大池化
最大池化MaxPool
即取局部值最大的点 下采样
保留输入特征同时减小数据量
(MaxUnpool 上采样)
1 | CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False) |
在输入图像上每次取池化核大小范围内的最大值(步长默认为核大小)
1 | input = torch.tensor([[1,2,0,3,1], |
非线性激活 Non-linear Activations
常用非线性激活
ReLU SIGMOID
1 | # 以ReLU为例 input<0 output=0, input>=0 output=input |
线性层 Linear Layers
Normalization Layers
BatchNorm2d 防止过拟合
Dropout Layers
随机失活 防止过拟合
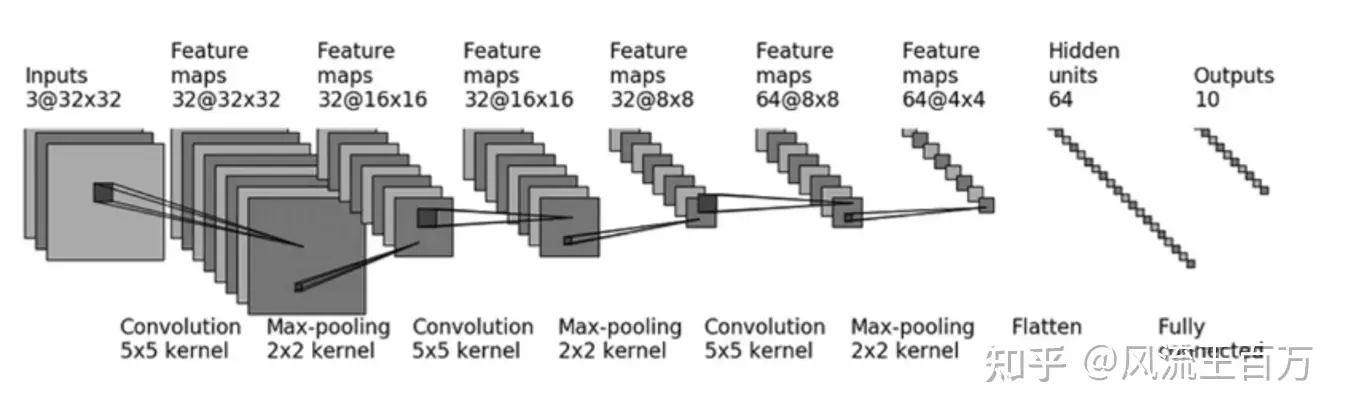
Sequential && Sifar model structure
以SIFAR10数据集及其模型为例
1 | import ssl |
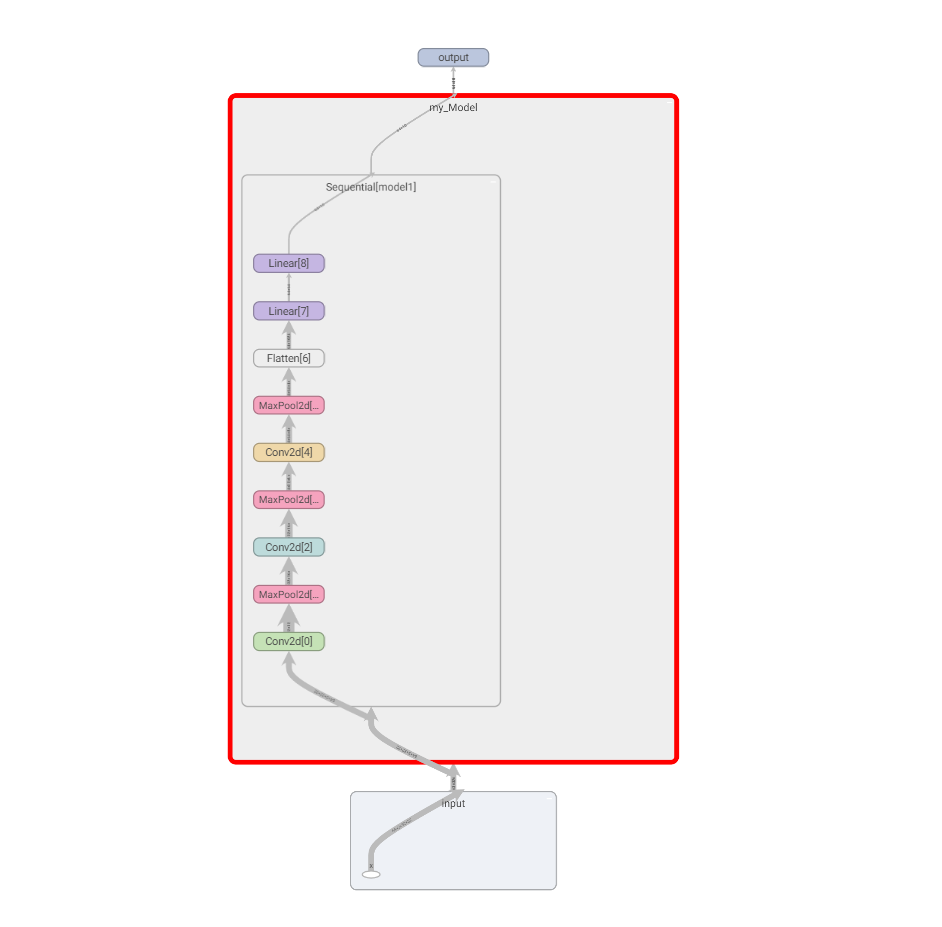
可视化
1 | # cmd 该环境下 |

损失函数 && 反向传播 && 优化器
1 | # 以CIFAR10数据集为例 使用上述模型 |
报错;

解决:
1 | import ssl |
现有模型使用及修改
VGG16模型
1 | import torchvision |
模型保存
1 | # 模型保存与加载 |
完整模型训练套路
1 | from model import * # 引入model |
看这里啦
https://pytorch.org/docs/stable/nn.html
google colab